Comparing Objects
Comparing Objects Using the Image Object Table
To open this dialog select Image Objects > Image Object Table from the main menu.
This dialog allows you to compare image objects of selected classes when evaluating classifications. To launch the Configure Image Object Table dialog box, double-click in the window or right-click on the window and choose Configure Image Object Table.
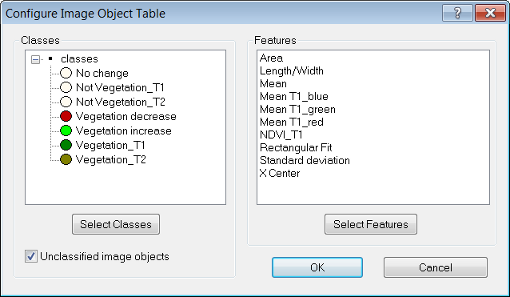
Upon opening, the classes and features windows are blank. Press the Select Classes button, which launches the Select Classes for List dialog box.
Add as many classes as you require by clicking on an individual class, or transferring the entire list with the All button. On the Configure Image Object Table dialog box, you can also add unclassified image objects by ticking the check box. In the same manner, you can add features by navigating via the Select Features button.
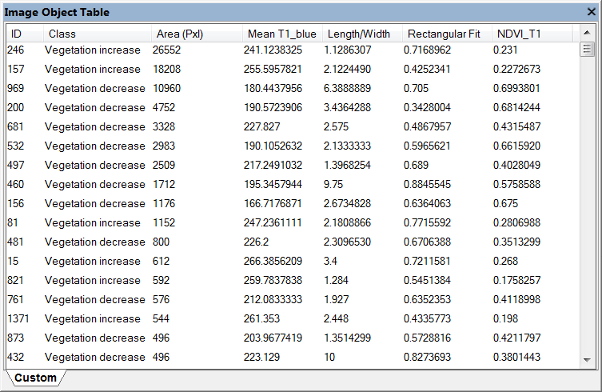
Clicking on a column header will sort rows according to column values. Depending on the export definition of the used analysis, there may be other tabs listing dedicated data. Selecting an object in the image or in the table will highlight the corresponding object.
In some cases an image analyst wants to assign specific annotations to single image objects manually, e.g. to mark objects to be reviewed by another operator. To add an annotation to an object right-click an item in the Image Object Table window and select Edit Object Annotation. The Edit Annotation dialog opens where you can insert a value for the selected object. Once you inserted the first annotation a new object variable is added to your project.
To display annotations in the Image Object Table window please select Configure Image Object Table again via right-click (see above) and add the Object feature > Variables > Annotation to the selected features.
Additionally, the feature Annotation can be found in the Feature View dialog > Object features > Variables > Annotation. Right-click this feature in the Feature View and select Display in Object Information to visualize the values in this dialog. Double-click the feature annotation in the Object Information dialog to open the Edit Annotation dialog where you can insert or edit its again.
Comparing Features Using the 2D Feature Space Plot
This tool allows you to analyze the correlation of two features for image objects. If two features correlate highly, you may wish to deselect one of them from the Object Information or Feature View windows. As with the Feature View window, not only spectral information maybe displayed, but all available features.
- To open 2D Feature Space Plot, go to Tools > 2D Feature Space Plot via the main menu
- The fields on the left-hand side allow you to select the levels and classes you wish to investigate and assign features to the x- and y-axes
The Correlation display shows the Pearson’s correlation coefficient between the values of the selected features and the selected image objects or classes.

Accuracy Assessment Tools
Accuracy assessment methods can produce statistical outputs to check the quality of a classification result regardless of the method used to classify the image objects.

- Choose Tools > Accuracy Assessment on the menu bar to open the Accuracy Assessment dialog box.
- In the Confusion Matrix drop-down list, select one of the following methods for accuracy assessment:
samples - select if you want to calculate and visualize the confusion matrix based on sample objects within a single project.
file (flattened) - select if you want to calculate and visualize the confusion matrix across multiple projects within the workspace based on the exported flattened confusion matrix results.
object variable - select if you want to calculate and visualize the confusion matrix based on objects defined as samples via an object variable within a single project.
- A project can contain different classifications on different image object levels. Specify the Image object level of interest by using the level drop-down menu.
- A project can contain ground truth information stored in Image object variables. For the selection of Confusion Matrix based on object variable select the corresponding variable name in this drop-down menu. This option is only activated for selection of Confusion Matrix based on object variable.
- Classes - To select classes for assessment, click the Select classes button and make a new selection in the Select Classes for Statistic dialog box. By default all available classes are selected. You can deselect classes through a double-click in the right frame.
- Load file (flattened)- This option is only activated for the selection of Confusion Matrix based on file (flattened) and lets you import and visualize an existing flattened file. This file can be created using the export algorithm Export Confusion Matrix .
- To view the accuracy assessment results, click Show statistics. To export the statistical output, click Save statistics. Enter a file name in the File name field and save the table in *.csv, *.txt or *.tcsv file format. The statistics file will be saved in the workspace root folder by default.
Confusion Matrix
The Confusion Matrix dialog box displays different statistic types used for accuracy assessment.
Test areas are used as a reference to check classification quality by comparing the classification with reference values (called ground truth in geographic and satellite imaging) based on pixels.
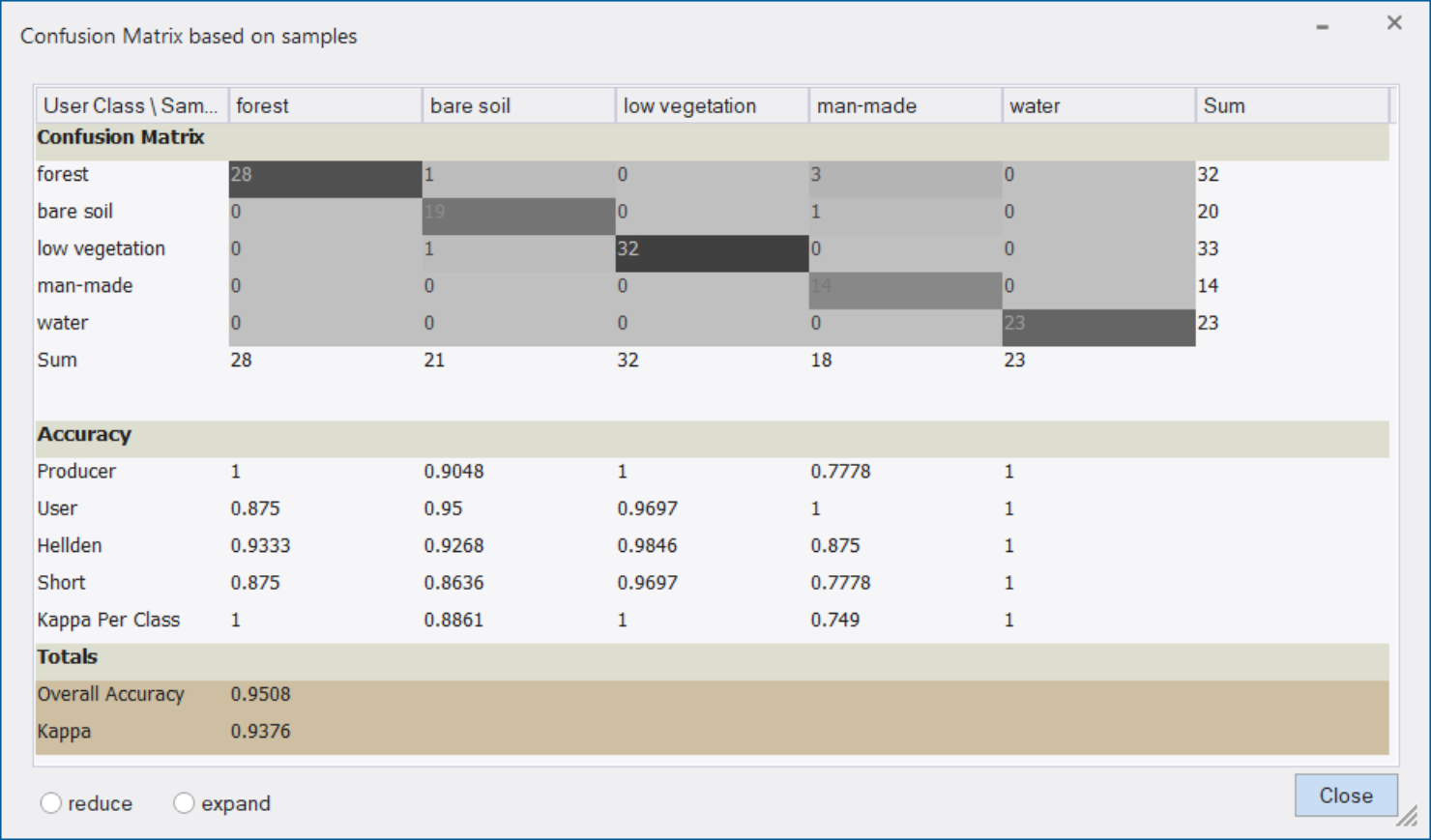
This statistic type considers samples (not pixels) derived from sample inputs. The match between the sample objects and the classification is expressed in terms of parts of class samples.
The Confusion Matrix dialog box displays the following statistics used for accuracy assessment:
User Class / Sample
The vertical column shows the user classes. The rows in horizontal direction reflect the sample/reference data.
Sum
The Sum row shows the number of objects/pixels that should have been identified as a given class, according to the sample/reference data.
Producer
The producer's accuracy is a false negative, where objects/pixels of a known class are classified as something other than the reference class.
User
The user's accuracy calculates false positives, where objects/pixels are incorrectly classified as a known class.
Hellden
The Hellden index is a mean accuracy index and denotes the probability of a randomly chosen point of a user class and its correspondence of the same class in the same position in the sample/reference data.
Short
The Short’s mean accuracy calculates the ratio of the estimated and sample/ ground truth classes intersection to their union.
Kappa per class
The Cohen's Kappa coefficient (see below) identifies the agreement that is expected when classes are totally independent while Kappa per class calculates the same agreement at per-classes level.
Overall accuracy
The overall accuracy calculates the proportion of pixels out of the reference sites/ground truth sites that were mapped correctly. The overall accuracy is usually expressed in percent, with 100% accuracy being a perfect classification - all reference objects were classified correctly. Range [0,1].
Cohen's Kappa
The Kappa coefficient measures the agreement between two sets - a classification result and ground truth objects/samples, while correcting for agreement that occurs by chance. This statistic is useful for measuring the predictive accuracy in a classification matrix. The Kappa coefficient can range from [-1 , 1], where a value for K = 0 is obtained when the agreement equals chance agreement and the upper limit of Kappa (+ 1.00) occurs only when there is perfect agreement between the two sets.
Polygons and Skeletons
Polygons are vector objects that provide more detailed information for characterization of image objects based on shape. They are also needed to visualize and export image object outlines. Skeletons, which describe the inner structure of a polygon, help to describe an object’s shape more accurately.
Polygon and skeleton features are used to define class descriptions or refine segmentations. They are particularly suited to studying objects with edges and corners.
A number of shape features based on polygons and skeletons are available. These features are used in the same way as other features. They are available in the feature tree under Object Features > Geometry > Based on Polygons or Object Features > Geometry > Based on Skeletons.
Polygon and skeleton features may be hidden – to display them, go to View > Customize and reset the View toolbar.
Viewing Polygons
Polygons are available after the first segmentation of a map. To display polygons in the map view, click the Show/Hide Polygons button (if activated deactivate Show or Hide outlines button first). For further options, open View > Display Mode > Edit Highlight Colors.
If the polygons cannot be clearly distinguished due to a low zoom value, they are automatically deactivated in the display. In that case, choose a higher zoom value.
Viewing Skeletons
Skeletons are automatically generated in conjunction with polygons. To display skeletons, click the Show/Hide Skeletons button and select an object. You can change the skeleton color in the Edit Highlight Colors settings.
To view skeletons of multiple objects, draw a polygon or rectangle, using the Manual Editing toolbar to select the desired objects and activate the skeleton view.
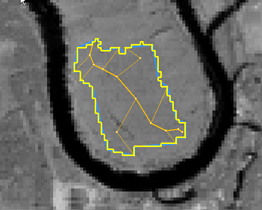
About Skeletons
Skeletons describe the inner structure of an object. By creating skeletons, the object’s shape can be described in a different way. To obtain skeletons, a Delaunay triangulation of the objects’ shape polygons is performed. The skeletons are then created by identifying the mid-points of the triangles and connecting them. To find skeleton branches, three types of triangles are created:
- End triangles (one-neighbor triangles) indicate end points of the skeleton A
- Connecting triangles (two-neighbor triangles) indicate a connection point B
- Branch triangles (three-neighbor triangles) indicate branch points of the skeleton C.
The main line of a skeleton is represented by the longest possible connection of branch points. Beginning with the main line, the connected lines then are ordered according to their types of connecting points.
The branch order is comparable to the stream order of a river network. Each branch obtains an appropriate order value; the main line always holds a value of 0 while the outmost branches have the highest values, depending on the objects’ complexity.
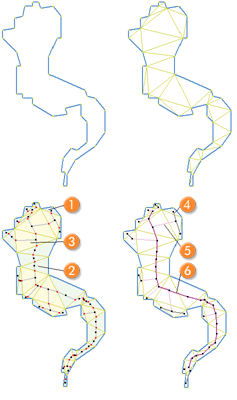
The right image shows a skeleton with the following branch order:
- 4: Branch order = 2.
- 5: Branch order = 1.
- 6: Branch order = 0 (main line).
